Free Updates For Databricks Databricks-Machine-Learning-Professional PDF Questions
Wiki Article
DOWNLOAD the newest Prep4sures Databricks-Machine-Learning-Professional copyright from Cloud Storage for free: https://drive.google.com/open?id=1TwW0DEf-RxmXSNY7Sg8Ezke5cS3o1Xof
The three versions of our Databricks-Machine-Learning-Professional training materials each have its own advantage, now I would like to introduce the advantage of the software version for your reference. On the one hand, the software version can simulate the real Databricks-Machine-Learning-Professional examination for all of the users in windows operation system. By actually simulating the real test environment, you will have the opportunity to learn and correct your weakness in the course of study. So that you can get your best pass percentage by our Databricks-Machine-Learning-Professional Exam Questions.
Databricks Databricks-Machine-Learning-Professional Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
| Topic 6 |
|
| Topic 7 |
|
| Topic 8 |
|
| Topic 9 |
|
>> New copyright Databricks-Machine-Learning-Professional Book <<
Pass Guaranteed Quiz 2026 Trustable Databricks-Machine-Learning-Professional: New copyright Databricks Certified Machine Learning Professional Book
However, preparing for the Databricks-Machine-Learning-Professional exam is not an easy job until they have real Databricks Certified Machine Learning Professional (Databricks-Machine-Learning-Professional) exam questions that are going to help them achieve this target. They have to find a trusted source such as Prep4sures to reach their goals. Get Databricks-Machine-Learning-Professional Certified, and then apply for jobs or get high-paying job opportunities. If you think that Databricks-Machine-Learning-Professional certification exam is easy to crack, you are mistaken.
Databricks Certified Machine Learning Professional Sample Questions (Q120-Q125):
NEW QUESTION # 120
A Machine Learning Engineer is building a fraud detection model that needs to use both pre- computed features from a feature table and real-time calculated features based on user location data sent with each inference request. The engineer has created a Python UDF called calculate_distance in Unity Catalog at main.fraud_detection.calculate_distance that computes the distance between a transaction location and the user's current location. The feature table main.fraud_detection.user_features contains historical user spending patterns with primary key user_id.
The engineer has written the following code to implement this scenario: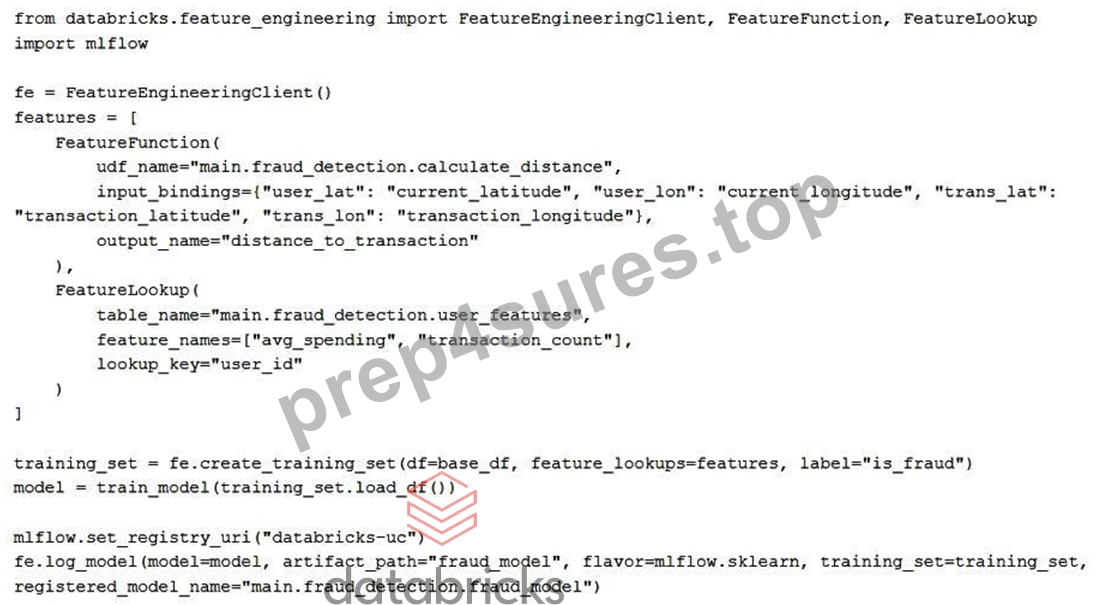
Which benefit of this implementation approach makes it suited to the real-time fraud detection use case?
- A. The Unity Catalog registry automatically creates REST API endpoints for UDF functions used in feature computation.
- B. The FeatureLookup function avoids the need for joining the full table main.fraud_detection.user_features with training_set increasing efficiency.
- C. The FeatureFunction caches computed distance values in the online store to improve inference latency for location pairs.
- D. The model automatically performs feature lookup and computation during inference without additional serving code.
Answer: D
Explanation:
By defining both FeatureLookup and FeatureFunction objects in the training set and logging the model with the FeatureEngineeringClient, the feature logic is packaged with the model. During inference, Databricks automatically performs feature lookups from the feature table and computes the on-demand distance feature using request-time inputs, without requiring any additional custom serving or feature-joining code. This makes the approach well suited for real-time fraud detection.
NEW QUESTION # 121
Why is Apache Spark useful for machine learning training?
- A. Web serving
- B. Data visualization
- C. GPU rendering
- D. Distributed data processing
Answer: D
Explanation:
Spark processes large distributed datasets efficiently.
NEW QUESTION # 122
A data scientist has developed a model to predict ice cream sales using the expected temperature and expected number of hours of sun in the day. However, the expected temperature is dropping beneath the range of the input variable on which the model was trained.
Which of the following types of drift is present in the above scenario?
- A. Feature drift
- B. Concept drift
- C. None of these
- D. Label drift
- E. Prediction drift
Answer: A
NEW QUESTION # 123
A Machine Learning Engineer is conducting hyperparameter tuning for multiple XGBoost models using Ray Tune on Databricks. They want to integrate MLflow tracking to monitor their experiments and need to ensure proper authentication. The engineer has Ray 2.41 installed and wants to use both Ray Tune and MLflow together in their distributed tuning workflow. They have to configure Databricks to run the hyperparameter optimization with MLflow integration. Which set of configuration steps will do this?
- A. Set MLFLOW_TRACKING_URI and MLFLOW_EXPERIMENT_TD environment variables before initializing Ray.
- B. Install the MLflow Ray plugin using %pip install mlflow-ray and configure the workspace connection.
- C. Enable MLflow autologging with mlflow.ray.autolog() and set the tracking server URI.
- D. Configure DATABRICKS_HOST and DATABRICKS_TOKEN environment variables before calling setup_ray_cluster().
Answer: D
Explanation:
When using Ray Tune with MLflow on Databricks, Ray workers must be able to authenticate back to the Databricks workspace to log runs to MLflow Tracking. Setting the DATABRICKS_HOST and DATABRICKS_TOKEN environment variables before initializing the Ray cluster ensures all Ray processes can securely communicate with Databricks and correctly log MLflow experiments during distributed hyperparameter tuning.
NEW QUESTION # 124
A data scientist wants to track the runs of their random forest model. The data scientist is changing the number of trees and the maximum depth of the trees in the forest across each run.
They write the following code block:
Which Python object type does params need to be an instance of?
- A. PySpark DataFrarne
- B. list
- C. array
- D. dict
Answer: D
Explanation:
The params variable must be a dictionary (dict) because mlflow.log_params() expects a dictionary where each key-value pair represents a parameter name and its corresponding value.
Additionally, the model instantiation RandomForestRegressor(**params) also requires params to be a dictionary to unpack the parameters correctly.
NEW QUESTION # 125
......
As you know, many exam and tests depend on the skills as well as knowledge, our Databricks-Machine-Learning-Professional study materials are perfectly and exclusively devised for the exam and can satisfy your demands both. There are free demos of our Databricks-Machine-Learning-Professional exam questions for your reference with brief catalogue and outlines in them. You can free download the demos of our Databricks-Machine-Learning-Professional learning prep on the website to check the content and displays easily by just clicking on them.
Databricks-Machine-Learning-Professional Practice Guide: https://www.prep4sures.top/Databricks-Machine-Learning-Professional-exam-dumps-torrent.html
- Reliable New copyright Databricks-Machine-Learning-Professional Book for Real Exam ???? Search for 《 Databricks-Machine-Learning-Professional 》 and download exam materials for free through ☀ www.testkingpass.com ️☀️ ????Latest Databricks-Machine-Learning-Professional Practice Questions
- 2026 100% Free Databricks-Machine-Learning-Professional –Valid 100% Free New copyright Book | Databricks-Machine-Learning-Professional Practice Guide ???? ➽ www.pdfvce.com ???? is best website to obtain ⇛ Databricks-Machine-Learning-Professional ⇚ for free download ????New Databricks-Machine-Learning-Professional Test Book
- Braindump Databricks-Machine-Learning-Professional Free ???? Examcollection Databricks-Machine-Learning-Professional Free Dumps ⚛ Databricks-Machine-Learning-Professional Practice Guide ???? Open website 「 www.troytecdumps.com 」 and search for ▶ Databricks-Machine-Learning-Professional ◀ for free download ????Databricks-Machine-Learning-Professional Valid Test Tips
- Databricks-Machine-Learning-Professional Practice Guide ✈ Braindump Databricks-Machine-Learning-Professional Free ☸ New Databricks-Machine-Learning-Professional Test Book ???? Search for ⮆ Databricks-Machine-Learning-Professional ⮄ on ▛ www.pdfvce.com ▟ immediately to obtain a free download ⏲Latest Databricks-Machine-Learning-Professional Test Answers
- Latest Databricks-Machine-Learning-Professional Practice Questions ???? Latest Databricks-Machine-Learning-Professional Practice Questions ???? Latest Databricks-Machine-Learning-Professional Practice Questions ???? The page for free download of 《 Databricks-Machine-Learning-Professional 》 on ▶ www.troytecdumps.com ◀ will open immediately ????Databricks-Machine-Learning-Professional Reliable Exam Pdf
- Latest Databricks-Machine-Learning-Professional Test Answers ???? Actual Databricks-Machine-Learning-Professional Test Pdf ???? Databricks-Machine-Learning-Professional Actual copyright ???? Search for ✔ Databricks-Machine-Learning-Professional ️✔️ on “ www.pdfvce.com ” immediately to obtain a free download ????Databricks-Machine-Learning-Professional Latest Test copyright
- Exam Databricks-Machine-Learning-Professional Pass4sure ???? Databricks-Machine-Learning-Professional Test Collection Pdf ???? Databricks-Machine-Learning-Professional Practice Guide ???? Immediately open 「 www.dumpsquestion.com 」 and search for ⮆ Databricks-Machine-Learning-Professional ⮄ to obtain a free download ????Databricks-Machine-Learning-Professional Reliable Test Voucher
- 2026 100% Free Databricks-Machine-Learning-Professional –Valid 100% Free New copyright Book | Databricks-Machine-Learning-Professional Practice Guide ‼ Open website ⇛ www.pdfvce.com ⇚ and search for [ Databricks-Machine-Learning-Professional ] for free download ????Databricks-Machine-Learning-Professional Latest Test copyright
- High-quality Databricks-Machine-Learning-Professional - New copyright Databricks Certified Machine Learning Professional Book ???? The page for free download of ➠ Databricks-Machine-Learning-Professional ???? on [ www.examcollectionpass.com ] will open immediately ????Databricks-Machine-Learning-Professional Reliable Exam Questions
- New Databricks-Machine-Learning-Professional Test Book ???? Databricks-Machine-Learning-Professional Reliable Exam Questions ???? Databricks-Machine-Learning-Professional Reliable Exam Pattern ???? Immediately open ☀ www.pdfvce.com ️☀️ and search for ▷ Databricks-Machine-Learning-Professional ◁ to obtain a free download ????Exam Databricks-Machine-Learning-Professional Pass4sure
- Test Databricks-Machine-Learning-Professional Tutorials ???? Examcollection Databricks-Machine-Learning-Professional Free Dumps ???? Databricks-Machine-Learning-Professional Latest Test copyright ???? Search for “ Databricks-Machine-Learning-Professional ” and obtain a free download on { www.examcollectionpass.com } ????Databricks-Machine-Learning-Professional Exam Questions Fee
- mariamsurk455836.tusblogos.com, thelegendlegacy.com, janaxucs656606.wikibuysell.com, stevezodu250560.elbloglibre.com, blakewzbn630786.blogs100.com, theokfun130366.thenerdsblog.com, social-medialink.com, harleyczyn310881.mdkblog.com, roxannzdca434478.wiki-cms.com, lms.m1security.co.za, Disposable vapes
P.S. Free & New Databricks-Machine-Learning-Professional dumps are available on Google Drive shared by Prep4sures: https://drive.google.com/open?id=1TwW0DEf-RxmXSNY7Sg8Ezke5cS3o1Xof
Report this wiki page